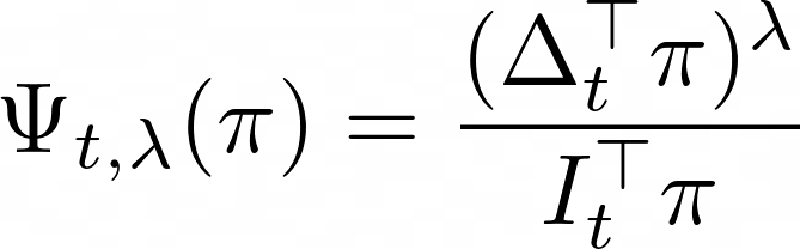
Logistics
Time: 4:00-5:00 PM; Wednesday 11/09/2022
Hybrid Lecture
Locations: Packard 202 Zoom Link
Presenter
Botao Hao
Research Scientist,
Deepmind, Mountain View
Abstract
Information-directed sampling (IDS) has revealed its potential as a data-efficient algorithm for reinforcement learning. However, when and how to use this design principle in the right way remains open. I will discuss two questions: 1. When can IDS outperform optimism-based algorithms? 2. What is the right form of information ratio to optimize for reinforcement learning? To answer the first question, I will use sparse linear bandits as a showcase and prove that IDS can optimally address the information-regret trade-off while UCB and Thompson sampling fail. To answer the second question, I will derive prior-free Bayesian regret bounds for vanilla-IDS that maximizes the ratio form of the information ratio. Furthermore, I will discuss a computationally-efficient regularized-IDS that maximizes an additive form of the information ratio and show that it enjoys the same regret bound as vanilla-IDS.
Reference
Bio
Botao Hao is a research scientist at Deepmind. Previously, he was a postdoc in the Department of Electrical Engineering at Princeton University. He received his Ph.D. from the Department of Statistics at Purdue University.