Austin
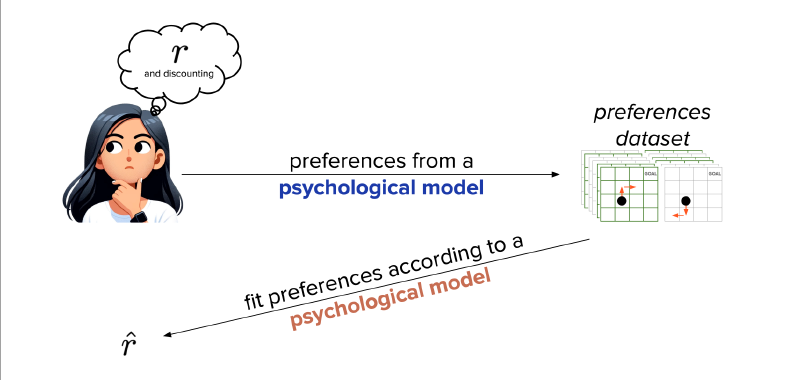
Building RLHF around psychological models of human preference
Alberta
Computing and Planning with Large Generative Models
Dale Schuurmans
Toronto
Challenges in Scalable Training Data Attribution
Roger Grosse
CMU
Recent Advances in Average-Reward Restless Bandits
Weina Wang
Alberta
Continual Subtask Learning
Adam White
1
2
…
4